Nillion Network Architecture for a PETs Ecosystem


Almost ten years ago, some of the current Nillion team members submitted a National Science Foundation research proposal that envisioned a decentralized secure storage and computation ecosystem in which node operators with various roles would enable, enhance, and monitor web-compatible apps and workflows over encrypted data. Today, we are finally seeing that vision come to life at Nillion as we build infrastructure and tools for creating competitive, usable apps that still protect user data. In this article, we discuss the philosophy and principles that motivate the architecture of the Nillion Network. We also present how the architecture's characteristics support a role-based PETs ecosystem that echoes and expands on the original vision.
Guiding Assumptions
Adopting a pragmatic approach, we acknowledge the realities that any new PETs infrastructure components and software artifacts inhabit today.
- Most apps use a combination of frameworks and services that best suit their target problem, and these almost always come from a number of incumbent and up-and-coming providers.
- It is difficult to predict today which PET components and features (or combinations thereof) will ultimately achieve product-market fit once PETs become ubiquitous.
- Incentive mechanisms for PETs throughout the industry are not yet mature and so it is not known who (user, service provider, or third-party node operator) will run PETs software or maintain PETs infrastructure.
Interoperability, Modularity, and Portability
The guiding assumptions motivate our strong commitment to three principles when designing and building software and infrastructure that can help developers employ PETs.
Interoperability: The languages, dependencies, and interfaces are chosen from among the most common and popular in contemporary app development (even if this comes at the expense of performance). This includes starting with Python and JavaScript/TypeScript SDKs, a NoSQL storage solution, REST APIs for all components, and so on. Developers should encounter as few obstacles as possible incorporating a Nillion PET feature into a typical stack (especially if they are incorporating only a single feature and/or using it in tandem with other solutions).
Modularity: Interdependencies between libraries/SDKs and infrastructure are kept to a minimum both within layers and between them. We can illustrate both by considering storage of encrypted data within nilDB. The blindfold library offers a number of encryption techniques, and any single technique can be used while ignoring the others. Furthermore, every available technique is compatible with nilDB nodes that are entirely independent of one another: no node necessarily needs to know the method of encryption or about which other nodes may be involved in a protocol.
Portability: The available functionalities and components are compatible with a number of stacks. Python and JavaScript/TypeScript SDKs and libraries accommodate both server-side and client-side app architectures, and containerization ensures that both service providers and third parties can operate nodes.
While ensuring that infrastructure and software are decentralized and incentivized can be a standalone goal, it is worth noting that following the above three principles naturally leads to solutions that are compatible with decentralization. In particular, it is easier to find and incentivize distinct kinds of operators (users with client devices, service providers, or third-party node operators) for each highly specialized modular component, with the component's portability providing flexibility in finding the best operator-component fit.
Software/Components and Enabled Ecosystem Roles
The latest launch introduced updated versions of a number of SDKs and components. Each of these makes it possible for a user, a service provider, or a third party to inhabit one or more roles in the overall PETs ecosystem. The relative independence of these roles ensures flexibility for developers and invites them to minimize trust assumptions and maximize decentralization when building new apps. This is particularly important because PETs can introduce new ways to separate roles that are traditionally inseparable. For example, a data aggregation service that operates a nilDB node need not also be an output data recipient because the aggregate result is computed by the operator only on ciphertexts that the operator does not possess the keys to decrypt.
Functional Node Operator Roles
Operators may choose to run one or more nodes that offer specific functionalities.
Storage Node Operator: An operator of a nilDB node supports data owners that need to store plaintext data, ciphertexts, or secret shares. An individual storage node operator need not have knowledge of clusters of nodes within which their node participates (and in which other nodes secret shares may be found).
Computation Node Operator: An operator of a nilAI node makes it possible for users to query LLMs that run inside TEEs.
Permission Node Operator: An operator of a nilAuth node confirms payments and authorizes access to functional (i.e., storage and computation) node operators. Functional node operators can choose to trust one or more nilAuth nodes, making it possible for trust relationships to be developed and mediated in a decentralized way.
Blockchain Node Operator: An operator of a nilChain node contributes to the maintenance of the blockchain and enables payments, rewards, and cryptoeconomic stake for the overall network.
Data Owner and User Roles
Data owners and users are typically on a client device or a browser and may have permission (1) to encrypt, store, and query data in nilDB nodes and/or (2) to submit queries to nilAI nodes. These permissions are independent of one another, so data owners and users can fall into one or more of the categories below.
Input Data Contributor: A data owner can have permission to write data to a nilDB node (but not necessarily permission to update or query that data).
Output Data Recipient: A data user can have permission to query data from a nilDB node (but not necessarily permission to write or update it).
AI User: A user can have permission to submit prompts to a nilAI node and to receive the outputs corresponding to those prompts.
Permission Delegator: Any user or operator that has permissions to perform some action has the ability to delegate any subset of that permission to a third party.
Attestation Verifier: Any user or operator that receives a nilAI node's execution attestation and has access to the source code that the node executed can verify that the source code corresponds to what was actually executed by the node.
Example Workflows
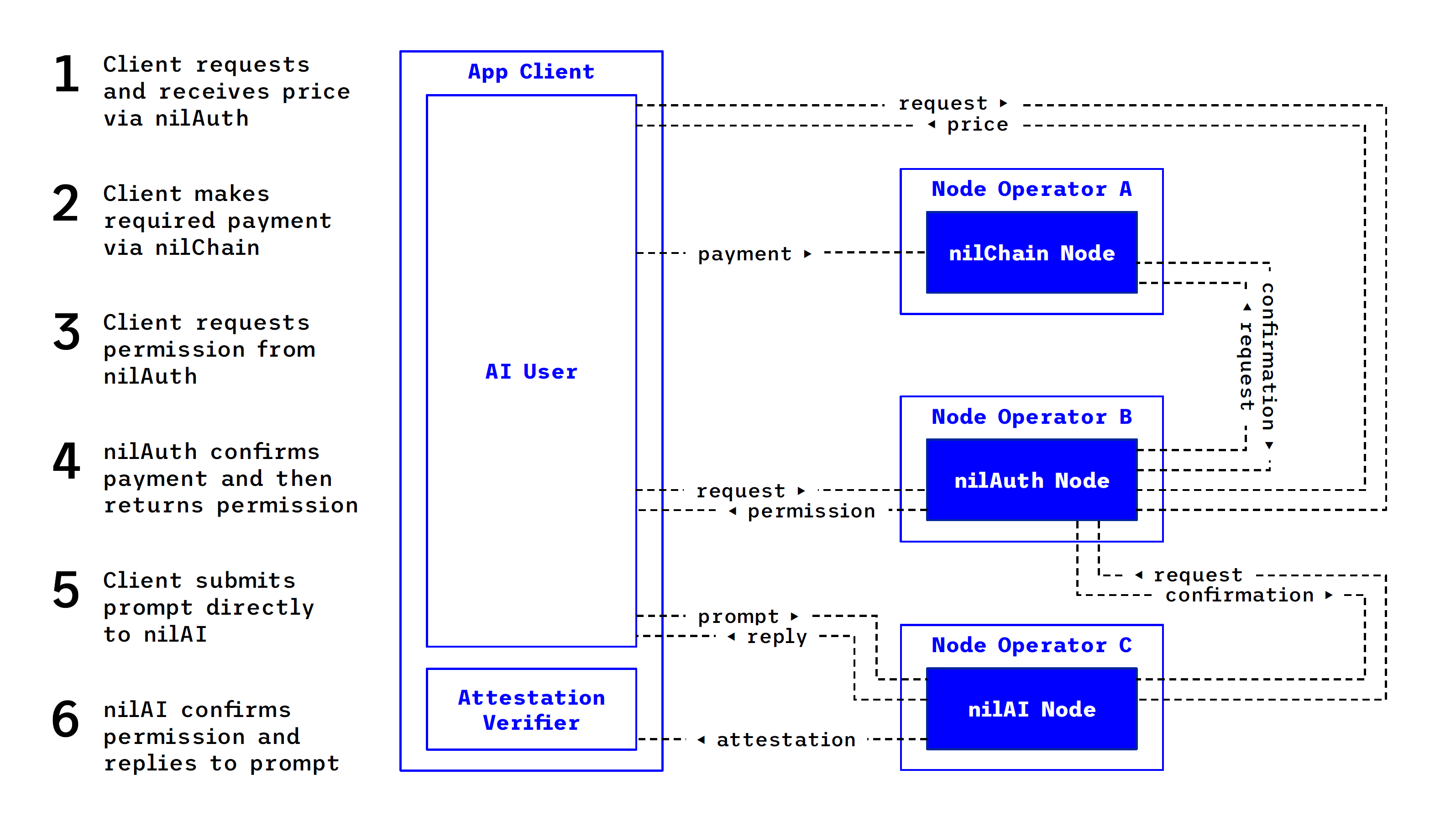
The diagram above illustrates a typical workflow between an app and nilAI. Note that the various roles are inhabited by distinct node operators and that the app client inhabits two roles. This workflow is similar to what occurs within @nilgpt_.
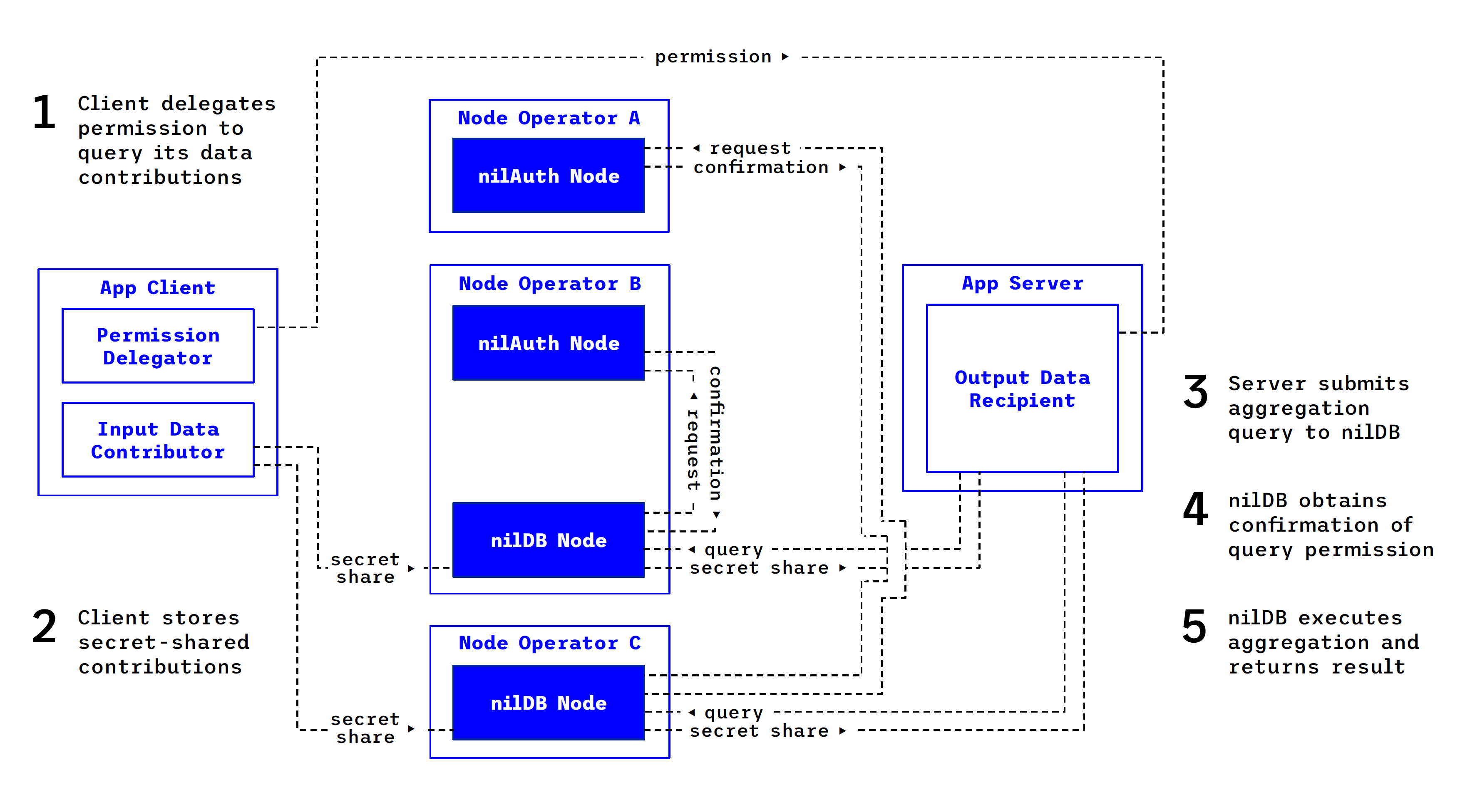
The diagram above illustrates a workflow in which an app contributes data (perhaps over time) towards an aggregation workflow that is conducted server-side. In this case, the app delegates permission to perform the aggregation in advance. When the server submits its query, this permission is confirmed by nilAuth. Note that in this example, one operator happens to inhabit two roles.
Looking Forward
Future work will introduce software and components that enable additional roles. These serve to assist users in confirming that network nodes are acting as specified.
Program Repository: A third-party operator can maintain a public list of queries, prompts, or programs that may be executed by functional node operators.
Audit Log Recorder: An operator of a nilDB or nilAI node could maintain a record of all executed actions. This way, users can query the audit log to determine whether the node behaved as intended. In the case of an MPC protocol, even one honest audit log recorder can provide assurance to users that the protocol was followed as prescribed.
The role-based view of the PETs ecosystem makes it possible to break down the development roadmap into manageable chunks while still maximizing the utility of what is built during each one. Future work will focus on developing software and components that further enable existing roles or introduce new ones. The modular, interoperable approach will also be leveraged to build integrations with peer projects that have complementary features.
Of course, the purpose of all of the above is to help developers build apps that minimize risk of data exposure and maximize user control over their data. In subsequent articles, we will discuss how the same incremental approach underpinning the development of the architecture (namely, acknowledging the status quo and building to work within it before enabling developers to transform it) is being applied to drive the app economy into a more privacy-compatible direction.